
Conquer Your Main Quest
v0.0.1
In the last article, I wrote about how I was selected to lead a new team at my company, Seeq, that would be responsible for infrastructure, developer experience, software delivery, production observability, and operations tooling. What I didn’t mention is that our product (also called Seeq) was primarily deployed on-premise at the time. Seeq started out as an on-premise web application. Each customer had to install it on one of their own servers on their own network. But in late 2020, things were starting to change. A couple of enterprising site reliability engineers (SREs), with the support of some other customer-facing roles, had taken our on-premise product, installed it in the cloud, and made it available to a few of our first, brave Software as a service (SaaS) customers.
This SaaS offering inspired the creation of a new infrastructure team, which we called Struct Squad. And Struct - as part of its software delivery responsibilities - would be on the hook for maturing the SaaS offering, building what we would eventually refer to as our platform.
The first version of our SaaS offering was very much a minimum viable product. A v0.0.1, if you will. Let me tell you about it.
First, and probably most surprising, it was multi-cloud: we had customers in both Azure and AWS. I’ll likely dig into why we went multi-cloud so early in a future article, since it was one of the biggest risks to my team’s success for years. For now, I’ll summarize: the main reason was that we had partnerships with both Microsoft and AWS.
In both clouds, each instance of Seeq - at least one per customer - was deployed on a single (except if they paid for our companion product Data Lab - more on that later) virtual machine running Linux.
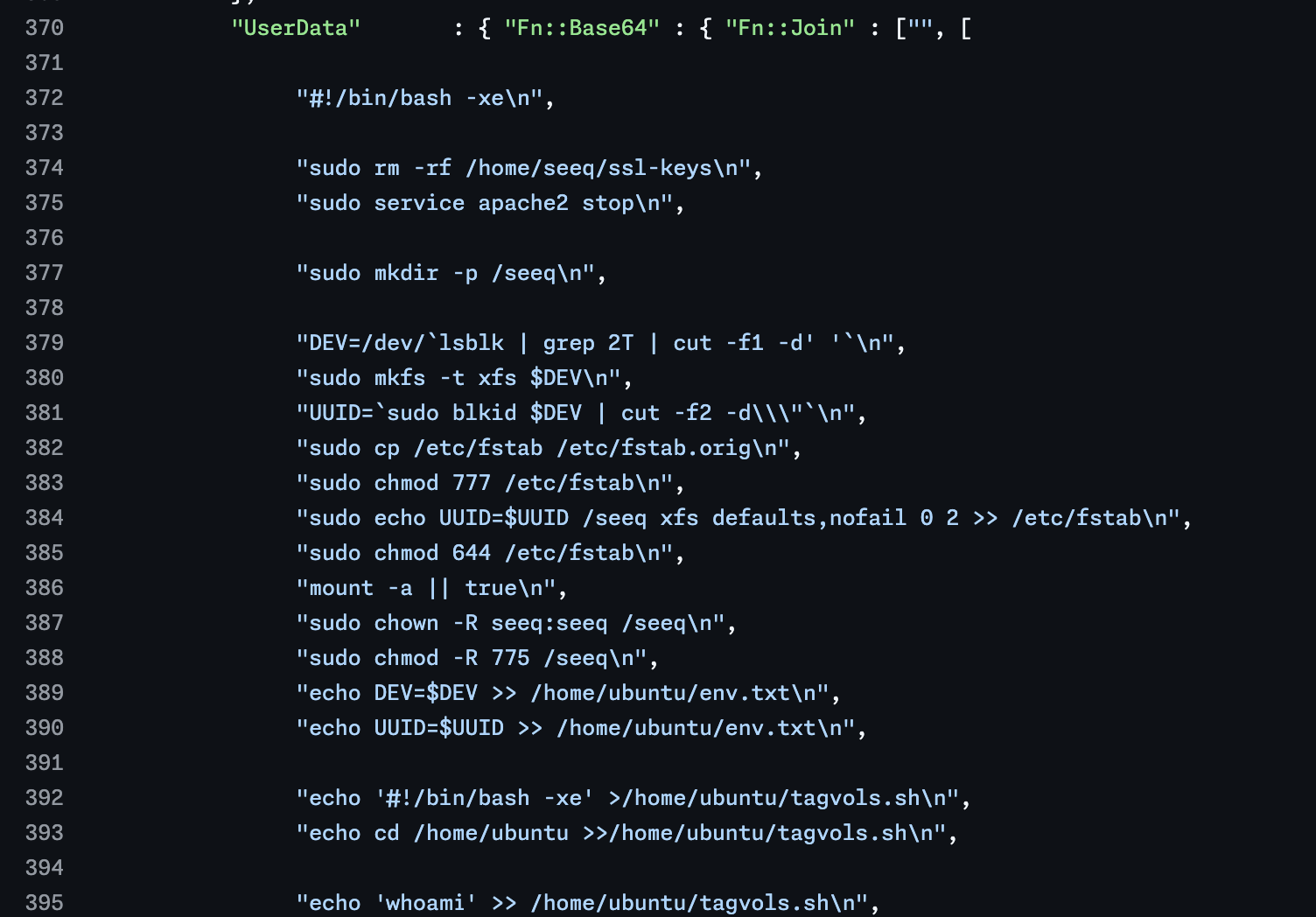
After that, things . . . diverged . . . between the cloud providers. In Azure, to deploy a new instance of Seeq with the necessary infrastructure, you’d create new Terraform files (probably by copying an existing Seeq instance’s files) and execute Terraform to create the virtual machine (VM) and other necessary infrastructure. From there, Chef would handle the initial Seeq installation. In AWS, to deploy a new instance, you’d load a CloudFormation template, fill out it’s parameters, and then CloudFormation would create the necessary infrastructure. Installation of Seeq was handled by including an install script in the user data of the EC2 instance created by CloudFormation. That code, in particular, was not very pretty. I’ve included a screenshot of a small snippet of that part of the CloudFormation template for those who like to look at bash code encoded in JSON arrays 👀. Don’t worry, I don’t judge.
In addition, if the customer wanted our Data Lab product, in AWS we would simply deploy another VM, install Data Lab, and configure it to connect to Seeq. However, in Azure, we had a series of bash scripts and YAML (and maybe more Terraform, I don’t remember exactly) that would create a Kubernetes cluster, install Data Lab on that, and connect it to Seeq.
Once the Seeq instance was deployed, things converged again between the cloud providers. Notably, upgrades were completely manual - meaning you had to SSH to the server and run commands - and usually involved coordinating with the customer, since they had to upgrade some components running on their server(s). Logs were sent to an Elasticsearch, Logstash, Kibana stack in AWS. Aside from that, there wasn’t much observability beyond what the cloud providers offered out of the box.
I tell you all of this because Struct, which included the enterprising SREs, some software engineers from other teams, and eventually some new hires were tasked with developing the next version of all this. We were expected to build something highly automated, secure, and usable on (at least implicitly) Kubernetes. And hopefully you now see it was going to be a lot of work.
The Problem
One of the first big problems we ran into was that we couldn’t make much meaningful progress on building anything new. At the beginning, all of us had prior responsibilities that we had brought with us. The SREs were still responsible for performing the deploys of new SaaS instances (and doing the manual upgrades, if memory serves). I had been working on the aforementioned Data Lab product and still was the de facto owner of it. And those are just two examples - there were many more.
So what do you do in situations like this where (probably important) work is preventing you from doing what you see as your main work? Sometimes I like to refer to my most important work or goal as my main quest and other - possibly distracting - work as side quests. How do you focus on your main quest? How do you reduce the time spent on side quests?
My experience is that there are several options for reducing time spent on any given side quest:
- Just stop doing it (abandon the quest)
- Get someone else to do it (offload the quest)
- Automate it in whole or in part (complete the quest)
Abandon the Quest
Abandoning side quests can (relatively rarely) be a viable option. If it is viable, this is almost always preferred. But you really need to be sure that the side quest isn’t necessary.
When making this decision, I recommend using something like a “Five Whys” exercise. Start by answering the question, “Why are we doing this?” and then ask yourself “Why?” to each subsequent answer four more times. I also recommend keeping the Principle of Production Purpose in mind; if you find it hard to map a responsibility to your company’s goals or your production software’s purpose it’s probably superfluous. Sometimes I’ll even suggest that we stop doing something that probably is necessary - usually with my tongue nestled cozily in my cheek - just to get everyone thinking about whether it’s really necessary.
When Seeq recently decided to eliminate Software Quality Engineer (SQE) as a role, we came across many examples of abandoning quests. Obviously, the elimination of the role was a big decision, and unfortunately a number of people were let go as a result. But this decision indicated that some of the responsibilities that the SQEs were handling weren’t necessary. An example of one of the things we eliminated was a software penetration test. When we inspected the test more closely we realized it had become essentially the same test that an SRE on my team was running on the same cadence (quarterly). So it was an easy decision to drop that test. Not all such decisions will be that easy - certainly not all of the responsibilities of the SQEs at Seeq were superfluous. We still care very much about the quality of our software, but we wanted to make quality fully the responsibility of our other engineers.
Of course, rather than carefully examining if something should be abandoned, you could take the United States Department of Government Efficiency’s approach. Simply fire people that you suspect might not be doing anything valuable and see if you’re right or not. Then if it turns out they were doing something valuable, try to hire them back. I’ll let you decide whether you think that’s a reasonable strategy.
Offload the Quest
Offloading the quest is the most straightforward scenario when a new team is created or if you’re trying to make room for your main quest. It’s also the simplest: ask someone else to do the side quest. Of course, the number one challenge you’ll run into here is that the other party you’re trying to offload it to doesn’t want it. The more it aligns with whatever they already own and the smaller the responsibility, the more success you’re likely to have. Sometimes you might have to get things to a certain state before someone else will take it over.
One thing to note here is that this offloading becomes a lot simpler if ownership is at the team level rather than the individual level. Let’s say I’m on the Foo team, I own the widgets API, and I’m moving to the Bar team. At that point we need to discuss whether I should offload ownership of the widgets API to someone on the Foo team or take it with me to the Bar team. However, if Foo owns the widgets API and I move from Foo to Bar, then I might need to do some knowledge transfer when I leave, but it’s clear that ownership of the widgets API should stay with Foo, not me. Unfortunately, at the time Struct Squad was formed, ownership was more often at the individual level. This ownership problem is something I’m still working to improve at Seeq to this day.
An example of something we offloaded when forming Struct Squad was Data Lab. I had been the lead developer on Data Lab, so when I moved teams there was some question as to whether I should take it with me. As it turned out, a third team - neither the team I left nor the new team - took on ownership of Data Lab. I had one knowledge transfer meeting with them, then answered occasional questions for months afterwards, but the ownership of Data Lab was completely off my (and Struct’s) plate.
Another thing we were able to offload were new deployments to AWS. It turned out that creating a new deployment with AWS CloudFormation was easy enough that our support team was willing to take over that process.
Complete the Quest
Some side quests are recurring manual tasks that must be done periodically. For example, deployments, reports, tests, etc. Automating a recurring task - completing the quest - is often the best option if you have the time.
One technique I’ve found especially helpful for beginning the automation of manual processes is the “do-nothing script”. This technique involves taking a checklist for a manual task and turning it into a script that tells you each step and waits for you to manually complete each step. And that’s it. You don’t actually have to automate any of the steps, but turning it into a script reduces the cognitive load and the activation energy required to do the task. Plus, it makes it that much easier to automate the task incrementally.
I used a do-nothing script (more or less - it did quite a lot actually) in combination with offloading to handle new deployments to Azure. Creating Terraform files, editing them, and figuring out exactly how to execute Terraform was more than the support team was willing to take on. So I created sq ops: a command line tool that started as a do-nothing script written in Python. It would run some git commands, prompt for deployment parameters, generate Terraform files, and then tell the user exactly what commands to run to apply the changes. See a screenshot of it in action below.
![Let me help you with an Azure SaaS deployment... First, let's see if you're on the develop branch... You are on "task/sajo/deploy-soxley." Would you like to switch to "develop"? [Y/n] n You are on branch "task/sajo/deploy-soxley," would you like to pull the latest? [Y/n] n I recommend we check out a new branch task/[initials]/deploy-[customer]-SUP-[number]. Would you like to do that? [Y/n] n What is the name of the customer you are deploying? soxley OK, I'll use 'soxley' for the files. Is this acceptable? [Y/n] What is the workorder number? (Press Enter for no workorder.) SUP- Is soxley.seeq.site the Seeq Server domain? Either press Enter to confirm or input a different domain to use. What is the Customer ID (for example C-111) you are deploying? C-123 OK, I'll use 'C-123'. Is this acceptable? [Y/n] What type of contract deployment is this? For example, Production, Test, PB3, etc. (do not use POV any longer)Test Select the location in which we are deploying this server. 0: Australia East 1: West Europe 2: South Central US 3: None of the above 1 What type of deployment will you be doing? 0: Seeq Server only 1: Seeq Server and SDL Server 2: SDL Server only 0 What version of Seeq are we installing? For example, R52.2.2-v202107240458. R52.2.2-v202107240458 What disk size will you deploy for the customer (in GB)? 0: 1024 1: 2048 2: 4096 3: I'll enter it myself 1 Approximately how many users will be using this server? 0: 1-10 1: 10-50 2: 51-150 3: 150-400 4: > 400 2 Based on 51-150 active users, I recommend we deploy Standard_D32s_v3. Either confirm this size by pressing Enter or input a different machine size.](/images/conquer-your-main-quest/sq-ops-picking-options.png)
Some steps still had to be done manually - even by the time we eventually retired the tool. Here’s an example of one of those manual steps:
def wait_for_pull_request(ctx):
current_branch = ctx.git.current_branch
ctx.ui.message(f'Go to https://github.com/seeq12/devops/compare/{current_branch}?expand=1 to '
f'create a Pull Request. Deployment will be done by "GitHub Actions"')
return PromptFlowStepResult(None, ctx)
With this tool completed, the support team was willing to take over the new Azure deployments, as well, freeing us from one more side quest so that we could focus on our main quest of building the next version of the SaaS platform.
If you want to get started with a do-nothing script, Dan Slimmon actually has a go framework for getting started. I’d also be happy to share the Python framework I created for my sq ops tool - feel free to reach out.
Pursue Your Main Quest
Once we had abandoned, offloaded, or completed our side quests, we were finally able to make some progress and eventually complete our main quest. I’ll tell you more about that in future articles.
In the meantime: what’s your main quest right now? What side quests are standing in your way? Are there any you should abandon? Offload? Complete?
Join My Mailing List
I have a mailing list where I write about topics that would be relevant to people who are just getting started creating or evolving a platform for their organization, or those that handle the platform responsibilities at companies that don’t have a dedicated platform team. If that sounds interesting to you, sign up for my mailing list below!